- Published on
An 'Easy' LeetGPU problem will teach you about GPU memory hierarchy
- Authors

- Name
- Filip Reka
Recently I was doing some LeetGPU problems and come across 1D convolution. It was marked as easy so I thought a very quick implementation might put me somewhere high.
My very simple implementation looked like this:
__global__ void convolution_1d_kernel(const float* input, const float* kernel, float* output,
int input_size, int kernel_size) {
int row = threadIdx.x + blockDim.x * blockIdx.x;
if (row < input_size - kernel_size + 1){
float val = 0.f;
for(int i = 0; i < kernel_size; ++i){
val += input[row + i] * kernel[i];
}
output[row] = val;
}
}
My submission was placed in 45th percentile with running time of 7.87ms. Rather mediocre position but I knew immediately that it can be made faster by preloading data to shared memory. It's easy to see that each element is loaded multiple times by different threads when kernels overlap (which happens if kernel size is larger then one, but with that size it not really a great convolution).
As you can see from graphics below, each thread calculates one output element using input data and kernel vector. Between colored dotted lines resides data that is used by each thread, so you an verify, that indeed it overlaps.
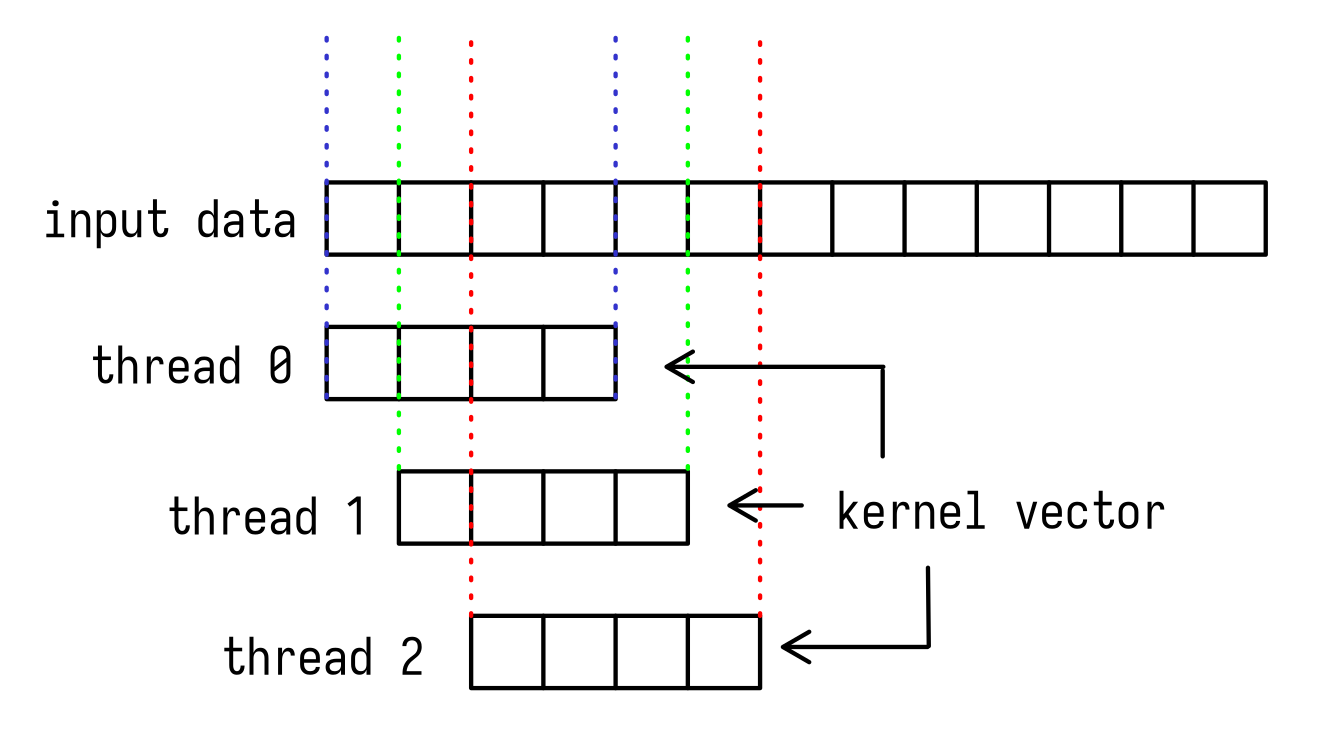
That's not good from performance stance, because reads from global memory that resides off chip are expensive. It is better to read data first into shared memory (on chip) and then use it afterwards. I've hopped on and wrote new kernel with using shared memory.
__global__ void convolution_1d_kernel(const float* input, const float* kernel, float* output,
int input_size, int kernel_size) {
int tdx = threadIdx.x;
int block_base = blockDim.x * blockIdx.x;
int row = block_base + tdx;
int tile_size = blockDim.x + kernel_size - 1;
extern __shared__ float shr_input[];
// load into shared memory
int load_idx = 0;
for(int i = tdx; i < tile_size; i+= blockDim.x){
load_idx = block_base + i;
if (load_idx < input_size){
shr_input[i] = input[load_idx];
}
}
__syncthreads();
if (row < input_size - kernel_size + 1){
float val = 0.f;
for(int i = 0; i < kernel_size; ++i){
val += shr_input[tdx + i] * kernel[i];
}
output[row] = val;
}
}
It is important to notice few things. First I defined dynamic shared memory buffer with extern. If you do so, you have to remember to pass it to your execution parameters like this:
size_t shared_mem_size = (threadsPerBlock + kernel_size - 1) * sizeof(float);
convolution_1d_kernel<<<blocksPerGrid, threadsPerBlock, shared_mem_size>>>(input, kernel, output, input_size, kernel_size)
Before that we need to calculate how much bytes we need. To threadsPerBlock we need to add a kernel_size - 1, because we need additional data for few most left elements. Idea is presented on image below.
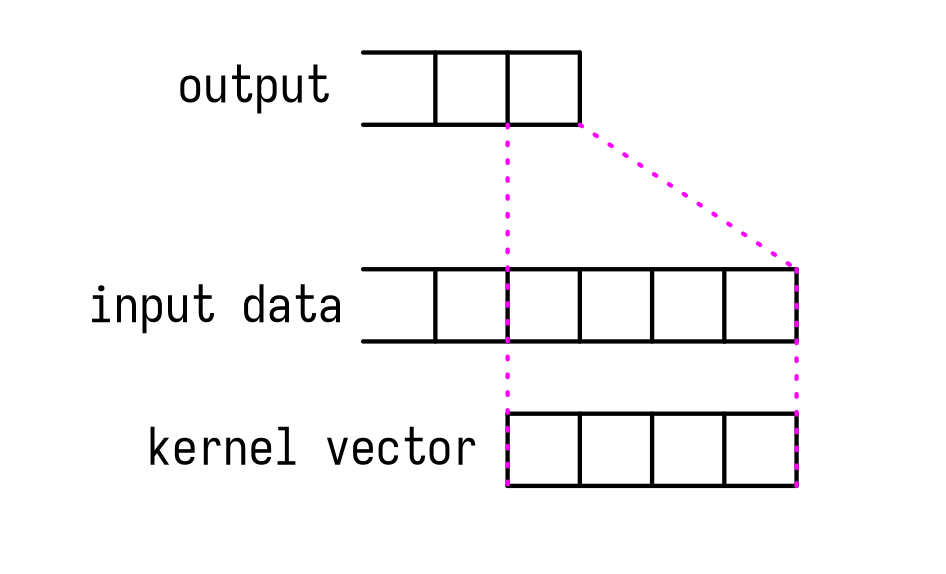
Loading data from global memory to shared memory is rather straightforward. Each thread loads one elements to buffer at a correct position, except few first that load two elements exactly because of the reason that I've explained earlier (we need more data then threads). Then we calculate output as usual.
Loading into shared memory helped a bit, but it only placed me in 54th percentile with execution time of 7.62 ms. Result is not as good as I thought I might be. I thought that I've already used all tricks up my sleave.
I decided to look at the top solution just to see if there is really some black magic happening there or if I did something wrong. I saw that they have been using some data declared with __const__ keyword. It was new to me. I quickly opened "Programming Massively Parallel Processors" (basically a CUDA Bible). In Chapter 7 they are talking about optimizing Convolutions and surprise surprise they talk about constant memory. I haven't read that far since I wanted to start doing some serious problems and stopped after first part of the book (Chapter 5). I thought that I got the basics pretty well covered but I guess I need to read more.
Constant memory is a special type of read-only memory that is optimized specifically to hold data that remains unchanged during kernel execution. It remains in GPU global memory, but has a dedicated cache. It is designed for scenarios, where all threads in a warp read the same address at the same time. In those situation it is read extremely fast because it's served from the constant cache. Constant memory works great in a convolution because kernel does not change throughout execution and it is read by all threads in a warp.
Solution with both optimizations in place:
__const__ float kernel_const[2048]; // problem's constrains state that 2048 is max kernel_size
__global__ void convolution_1d_kernel(const float* input, const float* kernel, float* output,
int input_size, int kernel_size) {
int tdx = threadIdx.x;
int block_base = blockDim.x * blockIdx.x;
int row = block_base + tdx;
int tile_size = blockDim.x + kernel_size - 1;
extern __shared__ float shr_input[];
// load into shared memory
int load_idx = 0;
for(int i = tdx; i < tile_size; i+= blockDim.x){
load_idx = block_base + i;
if (load_idx < input_size){
shr_input[i] = input[load_idx];
}
}
__syncthreads();
if (row < input_size - kernel_size + 1){
float val = 0.f;
for(int i = 0; i < kernel_size; ++i){
val += shr_input[tdx + i] * const_kernel[i];
}
output[row] = val;
}
}
// input, kernel, output are device pointers (i.e. pointers to memory on the GPU)
extern "C" void solve(const float* input, const float* kernel, float* output, int input_size, int kernel_size) {
int output_size = input_size - kernel_size + 1;
int threadsPerBlock = 256;
int blocksPerGrid = (output_size + threadsPerBlock - 1) / threadsPerBlock;
cudaMemcpyToSymbol(const_kernel, kernel, kernel_size * sizeof(float));
size_t shared_mem_size = (threadsPerBlock + kernel_size - 1) * sizeof(float);
convolution_1d_kernel<<<blocksPerGrid, threadsPerBlock, shared_mem_size>>>(input, kernel, output, input_size, kernel_size);
cudaDeviceSynchronize();
}
Shared memory is initialized with __shared__ keyword. In order to copy memory from host to this space on device we can use cudaMemcpyToSymbol function, parametrized just like on the code snippet.
With both optimizations I was placed in 94th percentile with 3.77 ms execution time. I am quite satisfied with this results.
If you want to learn more about shared memory I encourage to read Chapter 7 of PMPP where 2D convolution is implemented. Also, Simon Oz youtube video is a great resource to deepen your knowledge on this kind of memory.
Even tough the problem was marked as easy, I got to learn something new. I want to thanks people who are maintaining LeetGPU because it is great place to do some gpu programming and learn new stuff.